Hvordan tokens i språkmodeller fungerer

I denne artikkelen vil du få en grunnleggende forståelse av tokens: hva de er og hvorfor de er avgjørende i konteksten av språkmodeller. Det er ganske få som forstår hva tokens er eller hvordan de fungerer. Det å ha en grunnleggende forståelse av hvordan tokens fungerer kan være fordelaktig for de som jobber med eller er interessert i prompting.
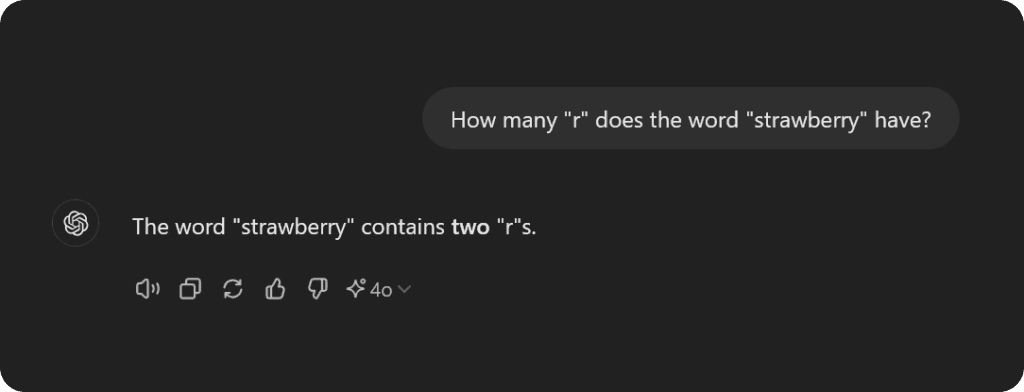
Lurer du på hvorfor modeller så ‘smarte’ som ChatGPT ikke klarer å telle hvor mange R-er det er i ordet 'strawberry'?
Tokens påvirker direkte mengden informasjon modellen kan behandle samtidig, kjent som kontekstvinduet, og dermed modellens evne til å opprettholde sammenheng i lengre interaksjoner. De har også en stor betydning for hvor nøyaktig svarene fra språkmodellen blir.
I løpet av denne artikkelen vil vi svare på flere nøkkelpunkter ved tokens:
- Hva er egentlig en token og hvordan fungerer de?
- Hvorfor er delord-tokens mer effektive enn tegn- eller ordbaserte alternativer?
- Hvordan påvirker tokens språkmodellenes evne til å behandle og generere språk?
- Hvilke praktiske implikasjoner har tokens for deg som driver med prompting?
- Hvilke teknikker kan brukes for å optimalisere tokens?
- Hvilket språk du bør prompte på?
Hva er en token?
For språkmodeller er tokens grunnleggende byggeklosser. De er små biter av tekst (også kjent som chunks) som modellene bruker for å ‘forstå’ og generere språk. Her er noen nøkkelpunkter om tokens:
- Tokens er små enheter som representerer språket vårt.
- Tokens lar språkmodeller forstå språk effektivt.
- Tokens er den minste enheten av tekst som AI-modeller prosesserer.
- Tokens har ikke en definert lengde. Noen er bare 1 tegn lange, andre er hele ord.
- Tokens kan være ord, delord, skilletegn eller spesielle symboler.
- Som en tommelfingerregel tilsvarer en token 3/4 av et ord. Så 100 tokens er omtrent 75 ord (engelske ord).
Hvorfor delord (ikke tegn eller ord) for tokens?
Et eksempel:
Her kan dere se at ordet “mismanaged” blir delt opp til to tokens, det samme med “overworked” (fargene representerer en token). “Readjustment” blir delt opp i tre tokens.
Delord er en måte å dele opp ord på for å forbedre språkforståelsen og effektiviteten til språkmodeller
Hvorfor ikke tegn, eller hele ord? La meg forklare...
Tegnbaserte metoder
Tegnbaserte metoder har flere ulemper. For det første gir hvert enkelt tegn svært lite meningsinnhold i seg selv. Dette fører til at vi må bruke lengre sekvenser for å formidle samme informasjon, noe som igjen krever mer datakraft. Tegn-tokens skaper unødvendig lange sekvenser, og dette gjør dem lite effektive i praksis.
En annen utfordring er at det blir vanskelig å forstå ords betydning, sammenheng og forhold til hverandre når vi bare ser på enkelttegn. Dette gjør treningen av språkmodeller basert på tegn-tokens mer komplisert og krevende. Kort sagt er tegnbaserte tilnærminger ofte lite hensiktsmessige for effektiv språkbehandling og forståelse.
Denne enkle setningen vil se slik ut med en tegnbasert metode: "Subword tokens are efficient."
# Tegnbasert vokabular:
["S", "u", "b", "w", "o", "r", "d", " ", "t", "o", "k", "e", "n", "s", " ", "a", "r", "e", " ", "e", "f", "f", "i", "c", "i", "e", "n", "t", "."]En fullstendig ordbasert tilnærming
En ordbasert tilnærming byr på flere utfordringer. For det første fører det til et enormt token-vokabular, siden hvert enkelt unike ord blir en egen token. Dette er lite effektivt både når det gjelder prosesseringsressurser.
Videre oppstår det problemer med ord som faller utenfor vokabularet. Modellen har rett og slett ingen måte å håndtere sjeldne eller nye ord på. I tillegg kommer utfordringer knyttet til feilstaving og ordvariasjon. Det er praktisk talt umulig å inkludere alle tenkelige variasjoner eller feilstavede versjoner av ord i modellens vokabular.
For å illustrere dette, må vi tenke oss at vi trenger egne tokens for ord som "rewriting" og "postprocessing". Men i realiteten kan vi fange betydningen av disse ordene perfekt ved å bruke bare to tokens for hvert ord. Dette viser hvor ineffektivt et rent ordbasert system kan være sammenlignet med mer fleksible løsninger.
Eksempel:
# Fullstendige ord vokabular:
["cat", "cats", "dog", "dogs", "running", "runner", "runners", ... tusenvis flere varianter]
# Delord vokabular:
["cat", "dog", "run", "ing", "er", "s", ... tusenvis flere varianter](Som dere ser her må man ha ekstremt mange ord i vokabulæret, samt vil det bli vanskeligere å treffe på feilstavelser av ord.)
Hva gjør delord-tokens så bra da?
Delord kombinerer det beste fra begge verdener samtidig som de reduserer begrensningene.
- Mindre vokabular. Delord reduserer vokabularet ved å bruke mindre og gjenbrukbare deler av ord.
- Håndtering av ukjente ord. Når en modell "ser" et ord for første gang, kan den bryte det ned i mindre deler. Fordi modellen kjenner delene, forstår den ukjente ord.
- Balanse mellom lengde og informasjon. Optimaliseringsmetoder finner de beste delord-kombinasjonene for et språk.
Oppsummert:
- Tegn-tokens er for små. De bærer for lite informasjon (mangler semantisk betydning).
- Ord-tokens er for store og skaper enorme vokabularer.
- Delord-tokens kombinerer mer effektive token-vokabularer med semantisk representasjon.
Flere eksempler på hvor delord-tokens utmerker seg:
Lange ord som består av mange tokens. Ved å bruke delord kan vi lage lange ord fra mindre tokens, og språkmodellene fanger deres betydning. Så delord-tokens er den optimale tilnærmingen.
Telling av ord, tegn og tokens
La oss bruke et reelt eksempel: Vi spør ChatGPT om å generere en kort beskrivelse av vikinger. Deretter teller vi antall ord, tegn og tokens.
Beskrivelsen har 117 tokens (eller 89 ord). Legg merke til at de fleste ord bruker enkeltstående tokens (ordene som er uthevet med en enkelt farge).
La oss gjøre en utregning:
For vår beskrivelse får vi omtrent 76 ord per 100 tokens. Dette er nært 75 (tommelfingerregelen).
Hva med tokens på ikke-engelske språk?
La oss se nærmere på det!
Telling av tokens på norsk.
Vi skal gjøre følgende:
- Oversette beskrivelsen til norsk
- Telle ordene og tegnene
- Telle tokens
Ser du forskjellen? Nå bruker de fleste ord flere tokens (ordene som er uthevet med mange farger).
La oss gjøre den enkle utregningen igjen:
For vår beskrivelse får vi omtrent 53 ord per 100 tokens (mye færre ord per 100 tokens enn på engelsk!)
Her er hovedårsakene:
- LLMs er hovedsakelig trent på engelsk tekst. Under treningen har de ikke "sett" nok norsk.
- Det norske språket har spesielle tegn som er ukjente i andre språk. Eksempler: æ, ø, å.
- Ord i norsk har ulike endelser. Det betyr at vi skriver det samme substantivet på mange forskjellige måter (for eksempel bestemt/ubestemt form, entall/flertall).
Implikasjonene av dette er:
- Engelske tokens er mer "effektive".
- LLMs har en tendens til å gjøre flere grammatiske feil på norsk.
- Bruk av språkmodeller på norsk er dyrere (siden vi betaler for token-bruk, ikke ordbruk).
Generelt vil jeg anbefale at man prompter på engelsk, men ber om å få output på norsk. Men det avhenger av use-case. Det finnes noen unntak der man burde prompte på norsk for å ‘aktivere’ mest mulig av treningsdataen på norsk, gjerne use-caser som tekstforfatting.
Telling av R-er i 'strawberry'
La oss gå over til det virale eksempelet som flere har snakket om og delt på sosiale medier: "How many R's are there in the word strawberry?" eller: "How many i are in antihistoricityness?"
Hvorfor sliter LLMs med oppgaver for førsteklassinger?
Hvis de er så "smarte", hvorfor kan de ikke få det riktig? Svaret vil kanskje overraske de fleste..
Språkmodeller vet ingenting om menneskelig språk.
Ja, du leste riktig. SPRÅK-modeller forstår ikke språket vårt. De vet ikke engang at de behandler tekst.
Når du snakker med ChatGPT (eller lignende), leser AI-modellen aldri teksten. Den leser bare den lange listen med tall (tokens). Når AI-modeller svarer, skriver de heller aldri tekst. De skriver listen med tall (tokens).
La meg beskrive hele prosessen forenklet steg for steg:
- Du sender din forespørsel til AI.
- Din forespørsel blir kodet (omgjort til tokens).
- LLM mottar listen med tokens.
- LLM genererer listen med tokens i svaret.
- Svaret blir dekodet til menneskelig språk.
- Du ser svaret på menneskelig språk.
Menneskelig språk er bare kode
Menneskelig språk kan ses på som en form for kode - et system vi har utviklet for å formidle tanker og ideer effektivt.
Tekst er koden som mennesker oppfant for å kommunisere raskere og bedre.
Mennesker ga navn (ord) til ting, aktiviteter, atferd og egenskaper. Vi bruker ord for å fange betydningen av alle disse tingene. Men "navnene" ble oppfunnet. Og det er derfor vi har så mange språk i verden.
Når noen sier "jordbær", forestiller de fleste for seg en søt, rød frukt. Men jeg har samme reaksjon når noen sier "strawberry," (som er det engelske navnet på jordbær). Fordi jeg også kan engelsk.
Men ordet i seg selv er bare en kode som vekker denne forestillingen i tankene mine. Fantasien min bryr seg egentlig bare om hva jordbæret representerer, ikke hvordan man staver det.
Språkmodeller fungerer som den menneskelige konseptforståelsen. De bryr seg ikke om hvordan vi skriver det ned. De fanger bare meningen med et jordbær.
Så hvordan fanger språkmodeller meningen? Det er her token-embeddinger kommer inn i bildet.
Token-embeddinger
Språkmodellen mottar en liste med tokens. Men tokennumrene er bare ID-er. Det er ingen mening i ID-er. For å få meningen blir tokens konvertert til vektor-embeddinger. Denne konverteringen skjer inne i de store språkmodellene.
Dette er litt forenklet, men her er den viktigste informasjonen:
- Språkmodellene har en såkalt 'oppslagstabell' for å matche token-IDer med token-embeddinger.
- Token-embeddingene trenes sammen med modellen for å finne de beste verdiene.
Dessverre har vi ikke tilgang til parametrene inne i GPT-4-modellene, så jeg kan ikke vise deg token-embeddingene for dem.
Men vi kan ta en titt på opensource modeller. La oss se på BERT-modellen, da det er enklest å vise der.
BERT Tokenizer
La oss se på “strawberry” eksemplet:
TokenIDs: [16876]
RawTokens: ["strawberry"]
Embeddings: tensor([[[ -3.3221e-01, -1.1379e-01, 6.3999e-01,
4.4558e-02, 8.5353e-01,
-1.0420e+00, 1.7256e-01, 1.3457e+00,
5.5995e-01, -1.2306e+00,
-5.1320e-01, 2.5210e-01, 4.0262e-01,
8.1291e-01, 5.0603e-01,
... en veldig lang vektor med 768 tall ]]])Dette er hvordan språkmodeller "forstår" ord - ikke som bokstaver eller lyder, men som komplekse matematiske representasjoner av mening.
Den 768-tall lange vektoren er hvordan språkmodeller fanger betydningen av et jordbær.
Dette er hvordan språkmodeller vet hva et jordbær representerer. Men det er ingen informasjon om den "menneskelige koden" (også kjent som menneskelig språk). Det er ingenting om hvilke bokstaver vi bruker for å representere et jordbær.
Disse vektorene er ikke en direkte representasjon av ordet "strawberry" eller "jordbær". De er en representasjon av betydningen av ordet.
Hva er problemet med "Hvor mange bokstaver...?" spørsmålet?
Når du sier "jordbær"ser jeg for meg et bilde av et jordbær i min fantasi, men hvis du spør meg "How many R's are there in the word strawberry?" så vil jeg se for meg det faktiske ordet og ikke frukten.
Dette illustrerer forskjellen mellom hvordan mennesker og maskiner "forstår" konseptet jordbær:

Språkmodeller har ikke den evnen!
De ser alltid det samme — vektor-embeddingene som er tilordnet "jordbær"-tokenen.
Et eksempel på vektor-embeddinger
I språkmodeller blir ord i en setning konvertert til numeriske tokens. Tokenene blir deretter konvertert til embeddings, som er høydimensjonale vektorer, som vist nedenfor.
INPUT: "Napoleon revolutionized milliatry organization"
↓ (Tokenizing)
TOKENS: [ [CLS], Napoleon, revolutionized, millitary, organisation ]
IDS: [ 101, 2024, 4046, 7890, 1042 ]
↓ (Embeddings Layer)
VECTOR: [ 0.0390, 0.0469, 0.0890, 0.0680, 0.0450 ]
[ 0.0370, 0.0479, 0.0879, 0.3725, 0.1220 ]Tokenbruk på kreativt formulerte ord
For de av dere som har sett noen av de tidligere promptsa mine, så har dere sikkert sett “forkorta” ord, kanskje til og med skrevet på en kreativ måte kjent som ‘leetspeak’ og andre måter.
De fleste trur til å starte med at denne ‘teknikken’ er for å få skviset inn en større prompt i context vinduet, men det har faktisk motsatt effekt. Du vil få en mye høyere token-count av og skrive ord på en uvanlig måte.
Se eksempelet nedenfor:
Som dere ser så bruker vi betraktelig flere tokens på å skrive ord på disse måten. Prcptn er tre tokens, tross det er en kortere versjon av Perception som er to tokens.
Så hva er fordelene med å gjøre dette da?
Når et spesifikt ord eller uttrykk blir nevnt i input, vil modellen ofte betrakte dette ordet som viktig for konteksten. Derfor øker sannsynligheten for at modellen gjentar det samme ordet eller lignende uttrykk i output.
Hvis du skriver 1337 istedenfor elite, eller Prcptn istedenfor Perception. Så forstår fortsatt språkmodellen hva ordet betyr (dette kan du fint dobbeltsjekke ved å spørre språkmodellen) men man reduserer da sannsynligheten for at ordet blir repetert i output.
Dette gjelder også ikke kun selve ordet du skriver, la oss si at i treningsdataen følges ofte ordet “elite” opp med ordet “player” på et senere tidspunkt i teksten, da vil det være en relativ høy sannsynlighet for at “player” også blir et av de neste ordene.
Neste token genereres alltid basert på de foregående tokenene (konteksten).
Se også min tidligere artikkel om hyperparametere i promptingprosessen for å få mer innsikt i tilgjengelige ord i autofullføring.
Nytt eksempel
Kontekst: "Jeg elsker å spise"
Eksempel på mulige neste token: "pizza", "is", "sushi"
Forklaring: Basert på de foregående ordene, forstår modellen at det neste ordet sannsynligvis er en matvare.
Derav kan du med denne metoden redusere sannsynligheten for at modellen følger opp med vanlige assosiasjoner knyttet til de originale ordene.
Dette er en metode som ikke er effektiv i forhold til tokens, så skal man bruke metoder som dette, bør man ha et veldig klart bilde av om den 'tradeoffen' er verdt det.
Ytelse og kostnader
Fokus på effektiv bruk av tokens forbedre modellens ytelse på flere måter:
- En bra prompt med ‘effektive tokens’ minsker muligheten for misforståelser, og hjelper modellen med å generere mer nøyaktige svar.
- Ved å eliminere unødvendige tokens sikrer du at modellens oppmerksomhet er rettet mot de viktigste aspektene av prompten.
Kostnader
Hvis man bruker OpenAI sitt API så betaler man for tokens, det er ingen månedlig fast kostnad. Du betaler rett og slett for bruk. De forskjellige modellene har forskjellige priser.
Dersom en hel organisasjon skal bruke et AI-produkt der man betaler for tokens, eller en AI-applikasjon med mange brukere- så vil tokens og kostnad være en faktor man må tenke på.
| Model | Pricing | Pricing with Batch API* |
|---|---|---|
| gpt-4o | $2.50 / 1M input tokens $1.25 / 1M cached** input tokens $10.00 / 1M output tokens | $1.25 / 1M input tokens $5.00 / 1M output tokens |
| gpt-4o-2024-08-06 | $2.50 / 1M input tokens $1.25 / 1M cached** input tokens $10.00 / 1M output tokens | $1.25 / 1M input tokens $5.00 / 1M output tokens |
| gpt-4o-2024-05-13 | $5.00 / 1M input tokens $15.00 / 1M output tokens | $2.50 / 1M input tokens $7.50 / 1M output tokens |
Dette er priser for OpenAI API på tidspunktet denne artikkelen ble skrevet, for å se nøyaktige priser se OpenAI sine hjemmesider
Noen key-takeaways avsluttningsvis
- En tommelfingerregel er at 100 tokens tilsvarer omtrent 75 engelske ord.
- Oftest vil du prompte på engelsk men be modellen svare på engelsk(Unntak i noen tilfeller- feks tekstforfatting på norsk)
- Kreativ bruk av forkortelser eller alternative stavemåter kan påvirke hvordan modellen behandler og gjentar ord i sine svar.
- Språkmodeller forstår ikke menneskelig språk direkte, men opererer med numeriske representasjoner
- Effektive tokens kan direkte påvirke modellens ytelse
- Antall tokens er relevant i forhold til kostnad via API
Håper dette ga dere litt innsikt i hvordan tokens fungerer, og hvorfor en tilsynelatende ‘smart’ teknologi kan slite med å stave ord som “strawberry.”
See you in the next one!